Model updates and prompt stability: what the data shows
Model updates break prompts in two ways: forced migration and silent drift. Data on version pinning, regression testing, and migration strategies from recent production incidents.

TL;DR: Model updates break prompts in two distinct ways - sudden forced migration (like the February 2026 GPT-4o retirement) and slow silent drift within a version. Teams that combine version pinning with automated regression testing report fewer incidents, but each strategy involves real tradeoffs. There is no single right answer.
When OpenAI retired GPT-4o on February 13, 2026, production teams had no soft landing. Parsers broke. Prompts that had passed evaluation for months suddenly failed. Teams that had pinned to GPT-4o in 2024 and never tested newer versions hit the hardest. The migration exposed a question worth examining: how do model updates actually affect prompt stability, and what do practitioners report about managing the risk?
This piece looks at incident reports from recent model transitions, benchmark data on prompt regression rates, and the four main strategies teams use in production.
Two kinds of instability
Not all model-related prompt failures work the same way, and the distinction matters for how you respond.
Prompt drift is the quiet one. Gradual, often unannounced behavioral changes happen within the same model version. A prompt that worked last Tuesday may produce subtly different outputs today, with no code change on your side. Research from Stanford and UC Berkeley (2023) documented measurable behavioral shifts in GPT-4 over a four-month period - same model ID, different outputs.
Prompt regression is the loud one. Explicit breakage happens when migrating to a new model version. The GPT-4o retirement forced teams to GPT-5, which expects different prompt conventions and structures outputs differently. Some teams' parsers broke on day one.
A 2025 Honeycomb survey found that 67% of teams running LLM workloads in production had experienced at least one model-related incident in the prior six months. Only 23% had automated regression testing - which is part of why the perceived failure rate looks so high.
What actually failed in the GPT-4o migration
GPT-5 was built to need less prompt engineering. OpenAI's documentation says it "follows instructions more naturally and requires fewer formatting constraints." That sounds like a feature. In practice, prompts optimized for GPT-4o's quirks sometimes performed worse on GPT-5, not better.
The most commonly reported failure modes during the migration were JSON output parsers breaking (GPT-5 produced valid but differently structured JSON), chain-of-thought prompts producing shorter reasoning traces, and strict formatting instructions being quietly deprioritized in favor of response quality.
Worth noting: plenty of teams reported the opposite. GPT-5's better reasoning and reduced hallucinations made prompts that didn't depend on model-specific quirks actually work better after migration. The data suggests the relationship between model updates and prompt stability depends heavily on how tightly a prompt was coupled to a specific model's behavioral patterns.
Four strategies, four tradeoff profiles
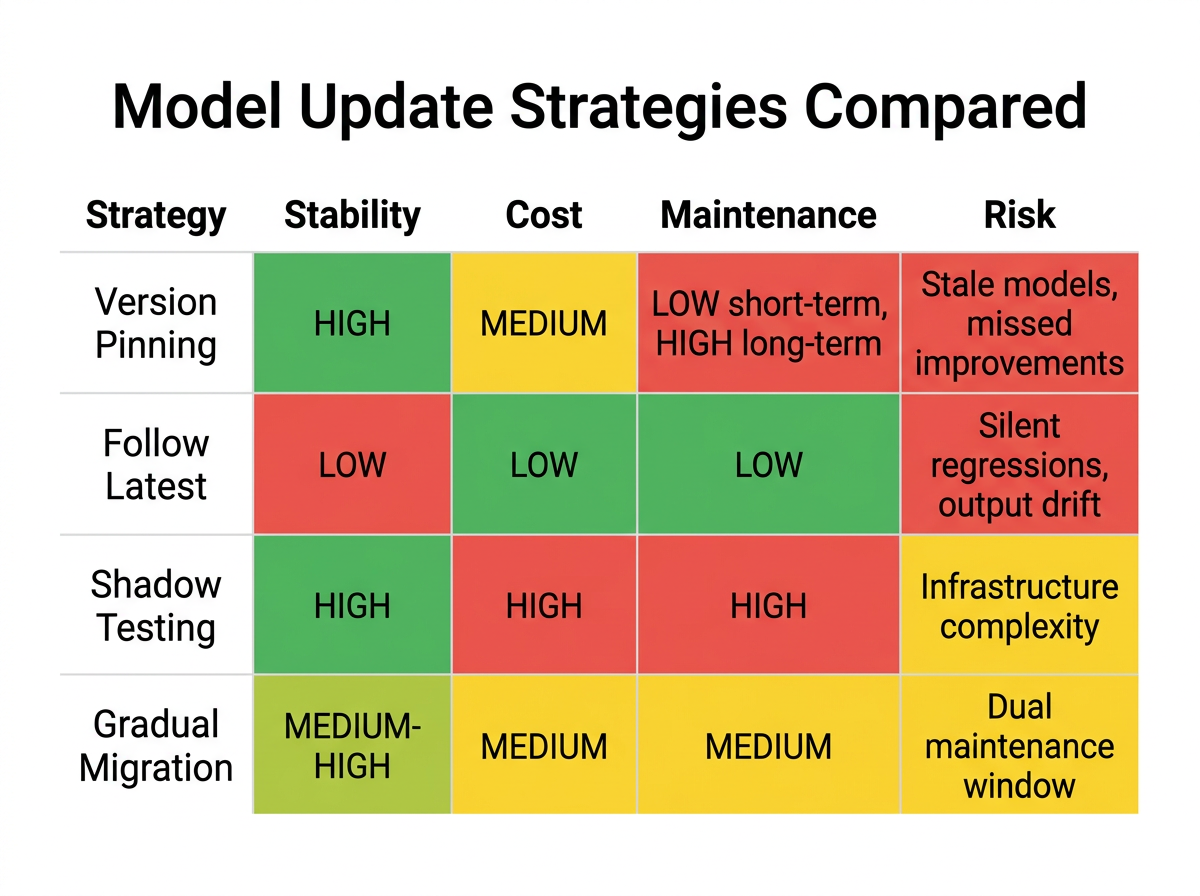
Pinning to a specific model snapshot removes surprise regressions. When outputs change, you know it was your prompt that changed, not the model. For regulated industries, this also matters for audit consistency. The downside: pinned versions get retired. Teams that pinned to GPT-4o in 2024 and never tested forward faced a harder migration in February 2026 than teams that had been gradually adapting.
Using an unversioned alias means zero migration overhead and automatic access to improvements. Developer reports consistently describe this as the highest-risk strategy for production systems with parsers or structured output requirements. Without version pinning, outputs can change without any action on your side, making regression detection nearly impossible at speed.
Shadow testing - running production traffic through both the current model and a candidate simultaneously - is the most comprehensive approach. Teams can catch regressions against real traffic patterns rather than just synthetic test cases. The cost is real though: it doubles inference spend during the testing window and requires infrastructure to route, compare, and analyze dual output streams.
Gradual migration with regression testing is the approach most often recommended in vendor documentation: pin current version, test candidate against a golden test suite, roll out gradually. Teams that use it report it balances stability with forward progress reasonably well. The ongoing cost is maintaining the test suite itself - golden tests become stale if not updated as the application evolves.
Regression testing in practice
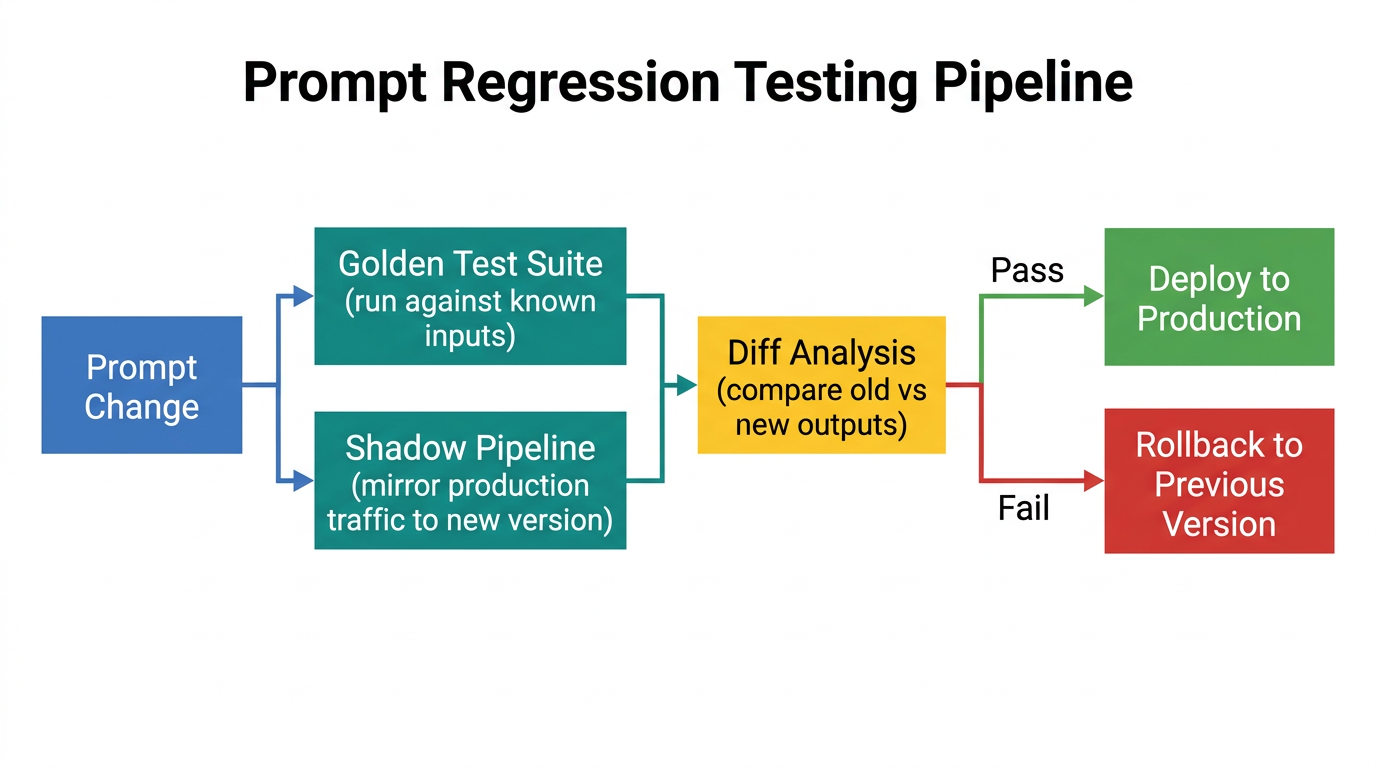
Regardless of strategy, the data suggests automated regression testing reduces incidents. The pipeline described most often in production postmortems: run a curated golden test suite against the candidate version, optionally mirror some production traffic via a shadow pipeline, compare outputs semantically (not just as strings), then gate deployment on a pass threshold. Tools like LangSmith and Langfuse offer evaluation frameworks built for this.
The effectiveness depends entirely on what is in the test suite. Teams report that 50-100 carefully chosen cases covering critical paths and known edge cases catch more regressions than thousands of synthetic examples. The hard limit: golden tests can only catch regressions for scenarios they already cover.
The multi-model dimension
An emerging pattern in 2026 is routing different tasks to different models within the same application: Claude for document analysis, GPT-5 for code generation, Gemini Flash for high-volume, cost-sensitive tasks. This changes the update calculus. Instead of one migration affecting the entire system, teams face more contained but more frequent update cycles. Multi-model routing appears to amplify whatever testing practices a team already has - for better or worse.
What the data suggests
Teams in regulated industries or with strict output format requirements tend toward version pinning with scheduled migration windows. Teams with strong testing infrastructure who want to stay current tend toward gradual migration with regression testing. High-volume, cost-sensitive teams often find shadow testing prohibitively expensive. Multi-model teams face a wider testing surface but benefit from isolated failure domains.
No strategy eliminates the risk entirely. Version pinning defers it. Testing catches known regressions but not novel ones. The most resilient teams in incident data combined pinning with automated regression testing and scheduled migration cadences, accepting higher ongoing maintenance cost for more predictable outcomes.
Related links
Stay in the loop
Get notified when we publish new posts. No spam, unsubscribe anytime.