When AI agents write their own prompts: what that means for prompt engineering
AI orchestrators now generate sub-agent prompts at runtime. Here is what that means for prompt engineering, governance, and the tooling gap teams are discovering in production.

TL;DR: AI agents increasingly generate their own prompts at runtime, creating a governance gap between traditional prompt engineering practices and how production AI systems actually operate. The skills remain valuable, but the application is shifting from writing individual prompts to designing the systems and constraints within which AI generates them.
Prompt engineering was supposed to be a core skill for the AI era. Learn to write great prompts, and you have leverage. Then multi-agent systems arrived, and the definition of "write" got complicated.
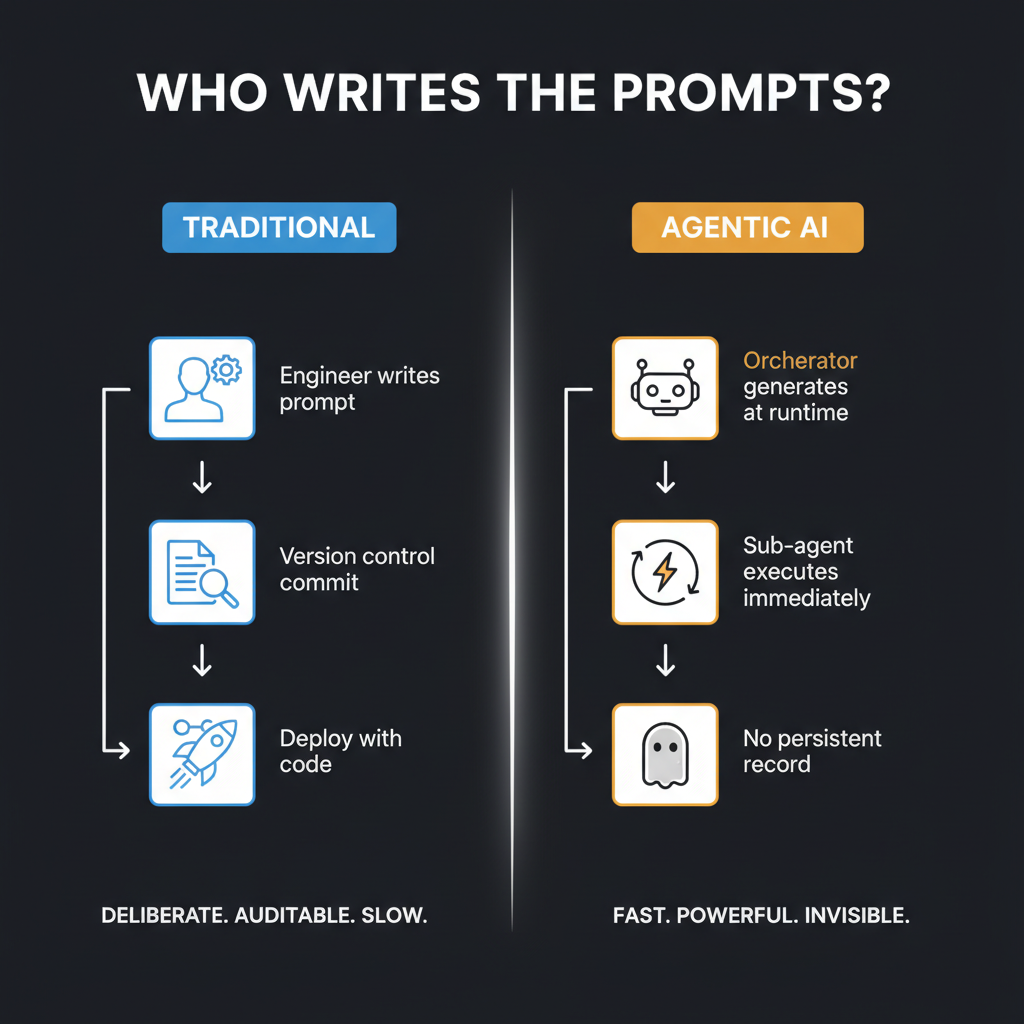
In production AI systems today, the orchestrator writes the sub-agent's prompt. A planning agent decides what instructions to give a coding agent. An evaluator generates new prompt variants based on what scored poorly last run. Humans are still involved, but they are increasingly authoring systems that author prompts rather than authoring prompts directly. That gap between intention and execution is the thing worth understanding.
What meta-prompting actually means
The term for this is meta-prompting: using an AI model to generate or modify prompts for other AI models. Research teams at Stanford and elsewhere have been working with it since at least 2022. What changed is that it moved from academic curiosity to production reality.
DSPy, released by Stanford in late 2023, treats prompts as learnable parameters and automates their optimization through a compilation step. Instead of manually engineering a prompt, you define the task signature and success criteria, and DSPy figures out the instructions. TextGrad takes a gradient-inspired approach: it optimizes text components by treating model feedback as a signal to propagate backward through the system. PromptBreeder uses self-referential mutation to evolve prompt populations without any human input at all.
The practical consequence is that many prompts running in live systems were never written by a human. They were generated, evaluated against a benchmark, and deployed by a pipeline. No one read them before they ran. That is the new normal for teams operating at scale.
Why this is happening now
The driver is scale. Multi-agent systems need prompts for every node in the graph. A research pipeline might spin up ten specialized agents per query: a planner, a web searcher, a summarizer, a fact-checker, a formatter, and several domain specialists. Writing, testing, and maintaining distinct prompts for all of them manually becomes a bottleneck fast.
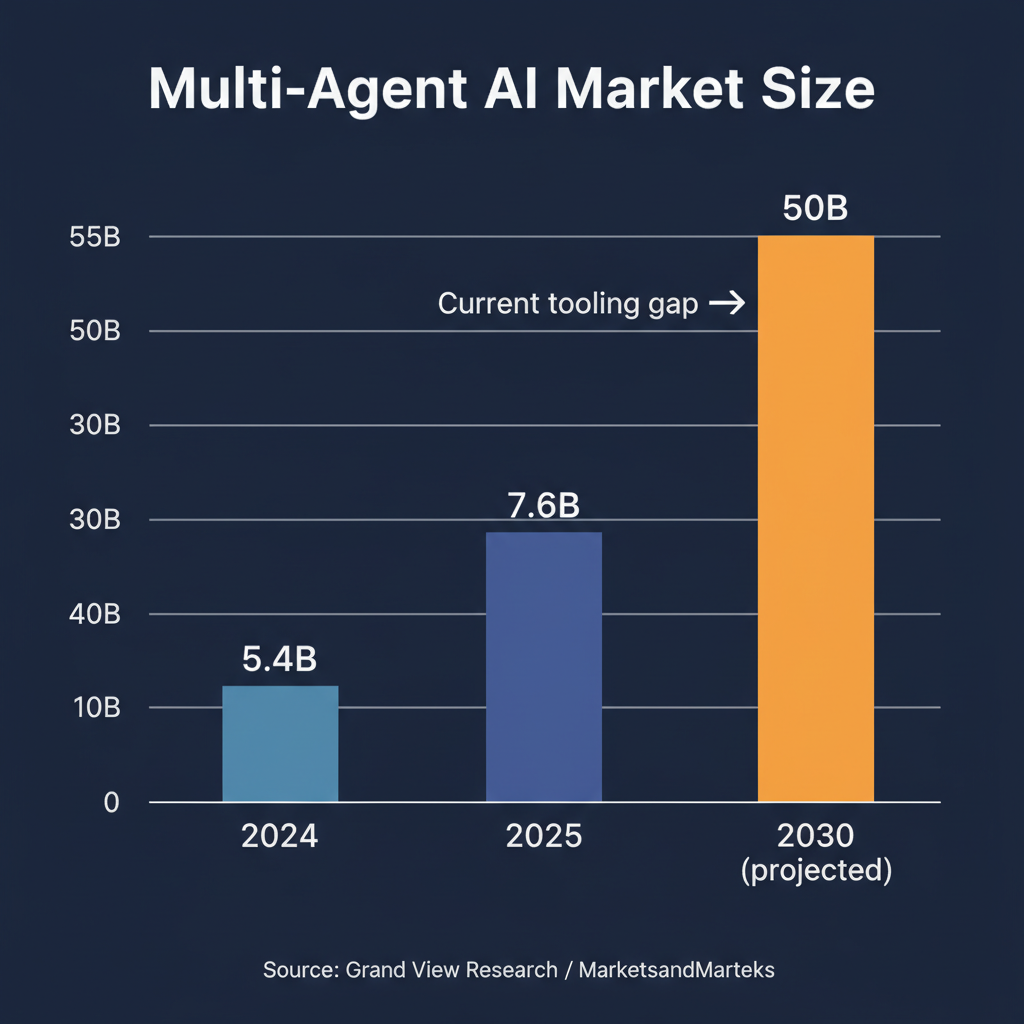
The market reflects the momentum. Multi-agent AI was a $5.4 billion industry in 2024. Projections from Grand View Research and MarketsandMarkets place it at $50 billion by 2030. At that growth rate, the infrastructure around multi-agent systems, including prompt management, cannot remain primarily manual.
There is also a legitimate adaptability argument. Static prompts have to anticipate every context a model might encounter. Dynamic prompt generation can adapt in real time to what just happened upstream, what a tool returned, or what a user's actual intent turned out to be. For long-running workflows with many dependencies, that real-time adaptation produces better results than any fixed instruction set could.
The governance gap
Traditional prompt engineering comes with a clear audit trail: a human writes a prompt, commits it to version control, has it reviewed, and deploys it with the code. When something goes wrong, you can trace it. There is a diff. There is an author. There is a commit message explaining why it changed.
Machine-generated prompts often have none of that. They are created at runtime, used once, and never persisted. You know the system that generated them, but not the specific instructions that executed. That creates a class of production risk that teams are only beginning to build tooling around.
Research published in early 2025 found that LLMs in multi-agent systems were compromised by adversarial instructions in 82.4% of cases when the attack vector was peer agent communication, compared to 41.2% for direct user input. When agents generate prompts for each other, the attack surface is every inter-agent message, not just what users type into a text field.
ServiceNow documented a real example: a second-order prompt injection where a malicious payload embedded in a retrieved document modified the instructions passed to a downstream agent. The workflow completed normally. No alarm fired. No human noticed a change. The only record of what actually ran was the output.

None of this makes prompt engineering obsolete. It relocates the skill. When AI generates the specific instructions, the human's job moves upstream: designing the system architecture that constrains what the AI can generate, writing the meta-prompts that guide the generation process, and defining the evaluation criteria that determine whether the outputs are safe and effective.
Some teams find this shift liberating. A prompt that took a week of manual iteration can now be optimized in hours by a system like DSPy. You set the objective and the guardrails; the system finds the wording. Others find it unsettling. The further a prompt gets from human authorship, the harder it is to intuitively understand why it behaves a certain way in edge cases. Both reactions are valid, and both sets of teams are working with the same underlying reality.
What tooling needs to catch up
Prompt versioning tools built for static prompts are meeting this new reality awkwardly. Most assume a human author making deliberate changes at identifiable points in time. Machine-generated prompt variants do not fit that model cleanly. An optimization run might produce thousands of candidates. Storing and auditing them requires different infrastructure than what a Git-like version history was designed for.
A few patterns are emerging from teams that have worked through this in production. First, version the meta-prompt and the generation system as the canonical artifact, not the individual generated outputs. The generated prompts are ephemeral; the system that creates them is what needs to be reproducible. Second, add evaluation gates before generated prompts enter production. If an AI produced a prompt, something should test it before it runs on real users. Third, capture lineage at the session level: which generation system, which seed instructions, which model version, which parameters. That is the minimum viable audit trail.
The field does not have settled answers yet. Tools are catching up to the practices, not the other way around. That is worth being honest about.
What the data suggests
The arc is clear. AI agents writing their own prompts is not a fringe experiment. It is the direction that production AI systems are moving, driven by the same economics and scale pressures that automate every other bottleneck in engineering.
Prompt engineering as a practice is not going away. The core skills, understanding model behavior, designing effective instructions, evaluating outputs at scale, are all more valuable than they were two years ago. What is changing is the layer at which those skills apply. Writing a single prompt well still matters. Designing the system that generates prompts well, and the infrastructure that governs them, is increasingly where the leverage is.
Related links
Stay in the loop
Get notified when we publish new posts. No spam, unsubscribe anytime.